AC自动机学习笔记

文章目录
【注意】最后更新于 January 31, 2021,文中内容可能已过时,请谨慎使用。
AC 自动机其实我去年就学过了,但当时大约只是会敲模板而已..现在几乎全忘光了。于是复习一下,顺便(较为本质地)讲解一下。
AC 自动机是什么?
说到这我真的想喷一下网上的各种教程..连“是什么”都不说清楚就开始讲“有什么用”和”怎么用“,怎能知其所以然?
形式上,AC 自动机基于由若干模式串构成的 Trie 树,并在此之上增加了一些 fail 边;本质上,AC 自动机是一个关于若干模式串的 DFA(确定有限状态自动机),接受且仅接受以某一个模式串作为后缀的字符串。
并且,与一般自动机不同的,AC 自动机还有 关于某个模式串的接受状态(我自己起的名字..),也就是与某个模式串匹配(以某个模式串为后缀)的那些状态。
关于 DFA,我在 SAM 学习笔记里 已经讲过了。
引用一下 2006 年集训队论文《王赟–Trie图的构造活用及改进》中的一张图:
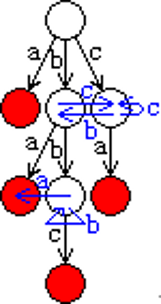
有了 AC 自动机,我们把一个文本串逐位地输入到自动机中,当匹配时就会处于接受状态。
AC 自动机怎样构建?
大致分为两个过程:
- 构建模式串组成的 Trie 树。
- 连 fail 边。
第一个过程不用讲吧。
fail 边是什么?
fail 边是 AC 自动机上一种特殊的边,其意义为:当 $u$ 在 Trie 树上没有字符 $c$ 的出边时,将 $\delta(u,c)$ 定义为 $\delta(fail(u),c)$(特例:初始状态若不存在某字符出边则连向自己,也可以理解为 $\forall c\in\Sigma,\delta(fail(start),c)=start$)。
另外,fail 边的作用类似于 KMP 算法中的 next 数组。
fail 边怎么连?
我们发现一个状态的 fail 边连向的其实就是这个状态的一个自动机上最长真后缀。
为什么呢..感性理解一下,失配了就不看前几位了..
然后就很好连了:对 Trie 树进行 BFS,将 $fail(\delta(u,c))$ 设为 $\delta(fail(u),c)$。因为一个串加上一个字符的最长真后缀就是这个串的最长真后缀加上这个字符..
另外,将 $\delta(u,c)$ 设为 $\delta(fail(u),c)$ 可以显式地在代码中完成。
再另外,要么 BFS 开始的时候将根节点的孩子入队,要么将 $fail(root)$ 的每个儿子都设为 $root$。否则根的儿子的 fail 边会连向自己。(也就是上文所述的“特例”。)
for (i = 0; i < 26; ++i) tr[0][i] = 1;
q.push(1);
while (!q.empty())
{
u = q.front();
q.pop();
for (i = 0; i < 26; ++i)
{
if (tr[u][i])
{
fail[tr[u][i]] = tr[fail[u]][i];
q.push(tr[u][i]);
}
else tr[u][i] = tr[fail[u]][i];
}
}
fail 树
由于每个点都只连出一条 fail 边,且连到的点对应的字符串长度更小,所以 fail 边构成了一棵 fail 树。
如果学过 SAM 的话,可能会发现 fail 树和 parent 树很像..实际上它们具有的性质是相同的,然而构成它们的状态不同——parent 树是所有 right 集合等价类(也就是 SAM 上的所有节点),而 fail 树是 Trie 上的每个前缀(也就是 AC 自动机上的所有节点)。
作为一个自动机,我还没讲 AC 自动机的接受状态是哪些..其实就是 Trie 树上的那些终止节点在 fail 树上的整个子树的并。
而 关于某个模式串的接受状态,也就是与某个模式串匹配(以某个模式串为后缀)的那些状态,就是那个串在 Trie 树上的终止节点在 fail 树上的子树。知道这个也就知道怎么用 AC 自动机进行多模式串匹配了(建出 fail 树,记录自动机上的每个状态被匹配了几次,最后求出每个模式串在 Trie 上的终止节点在 fail 树上的子树总匹配次数就可以了)。
洛谷 P3796 参考代码
#include <iostream>
#include <cstdio>
#include <queue>
#include <vector>
#include <cstring>
#include <algorithm>
using namespace std;
typedef pair<int, int> pii;
const int N = 160;
const int L = 80;
const int M = 1000010;
void add(int u, int v);
void dfs(int u);
int head[N * L], nxt[N * L], to[N * L], cnt;
int n, tr[N * L][26], fail[N * L], tot, suc[N * L], siz[N * L];
char s[N][L], t[M];
queue<int> q;
pii ans[N];
int main()
{
int i, j, u;
scanf("%d", &n);
while (n)
{
memset(tr, 0, sizeof(tr));
memset(suc, 0, sizeof(suc));
memset(siz, 0, sizeof(siz));
memset(head, 0, sizeof(head));
tot = 1;
cnt = 0;
for (i = 0; i < 26; ++i) tr[0][i] = 1;
scanf("%d", &n);
for (i = 1; i <= n; ++i)
{
scanf("%s", s[i]);
ans[i].first = 0;
ans[i].second = i;
for (j = 0, u = 1; s[i][j]; ++j)
{
int c = s[i][j] - 'a';
if (!tr[u][c]) tr[u][c] = ++tot;
u = tr[u][c];
}
suc[u] = i;
}
q.push(1);
while (!q.empty())
{
u = q.front();
q.pop();
for (i = 0; i < 26; ++i)
{
if (tr[u][i])
{
fail[tr[u][i]] = tr[fail[u]][i];
q.push(tr[u][i]);
}
else tr[u][i] = tr[fail[u]][i];
}
}
scanf("%s", t);
for (i = 0, u = 1; t[i]; ++i)
{
u = tr[u][t[i] - 'a'];
++siz[u];
}
for (i = 2; i <= tot; ++i) add(fail[i], i);
dfs(1);
sort(ans + 1, ans + n + 1);
printf("%d\n", -ans[1].first);
for (i = 1; i <= n && ans[i].first == ans[1].first; ++i) printf("%s\n", s[ans[i].second]);
scanf("%d", &n);
}
return 0;
}
void dfs(int u)
{
int i, v;
for (i = head[u]; i; i = nxt[i])
{
v = to[i];
dfs(v);
siz[u] += siz[v];
}
ans[suc[u]].first -= siz[u];
}
void add(int u, int v)
{
nxt[++cnt] = head[u];
head[u] = cnt;
to[cnt] = v;
}
一些例题
[TJOI2013]单词,基本上是道裸题。
[POI2000]病毒,不访问接受状态找环即可。
[NOI2011]阿狸的打字机,对 Trie 进行 dfs 并打根到当前点的标记,在 fail 树上统计子树标记和。我的题解
与 KMP 之间的关系
放在最后面是因为我认为 KMP 并不是 AC 自动机的前置知识..然而他们之间的确有着千丝万缕的联系。
「KMP 是个自动机」
要是早有人告诉我这句话估计我早就(真正地)学会 KMP 了..
KMP 自动机的主体是一条链,加上了一些“next 边”(其实就是 AC 自动机的 fail 边)。
而 KMP 自动机之于 AC 自动机,就像 SAM 之于广义 SAM。
也就是很多人常说的一句话:AC 自动机就是 Trie 上 KMP。
递归地计算转移函数
简介
“将 $\delta(u,c)$ 设为 $\delta(fail(u),c)$”这一步是可以不去显式完成的,并且,在绝大多数情况下(事实上我并不知道任何反例)这样做复杂度是线性的,可以将复杂度中的字符集大小去掉,并节省空间。
做法非常简单:当你需要 $\delta(u,c)$ 而其没有定义时,递归地去计算 $\delta(fail(u),c)$。
构建 fail 的过程复杂度为线性
一个节点到根的路径上这些点总共跳 fail 的次数不会超过其深度。
所以总共跳 fail 次数不会超过 Trie 树所有叶子的深度和。
证完了。
将字符串输入进自动机复杂度为线性
每输入一个字符串最多深度加一。
每次跳 fail 深度减一。
证完了。
评论正在加载中...如果评论较长时间无法加载,你可以 搜索对应的 issue 或者 新建一个 issue 。